ETL Process Optimization: A Practical Guide to Faster, More Reliable Data Pipelines
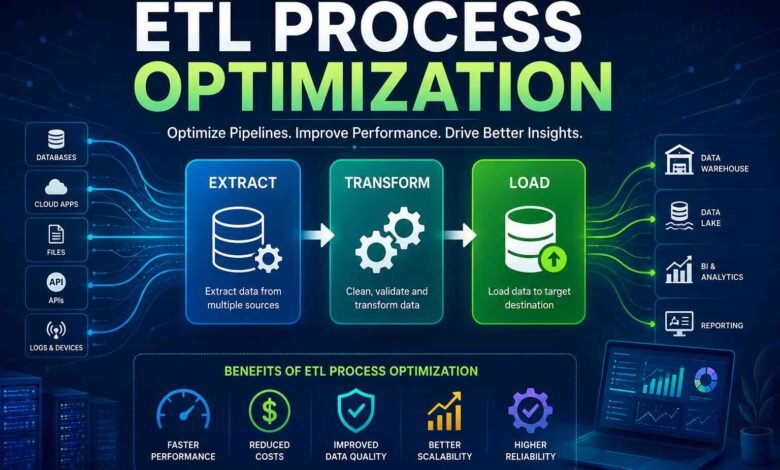
ETL process optimization focuses on improving the efficiency, speed, reliability, and scalability of Extract, Transform, and Load workflows. A well-optimized ETL pipeline reduces processing time, minimizes errors, lowers infrastructure costs, and ensures that business users receive accurate data when they need it. As data volumes continue to grow, optimization becomes an essential part of maintaining high-performing analytics and reporting environments.
Table of Contents
ToggleUnderstanding the ETL Process
ETL stands for Extract, Transform, and Load. It is a framework used to move data from various sources into a centralized destination such as a data warehouse, data lake, or analytics platform.
During the extraction phase, data is collected from databases, APIs, cloud applications, files, and other systems. The transformation phase cleans, validates, standardizes, and enriches the data according to business requirements. Finally, the loading phase transfers the processed data into a target system where it can be analyzed and used for reporting.
The effectiveness of an ETL workflow depends on how efficiently these three stages operate together. Poorly designed pipelines can create bottlenecks, increase costs, and delay access to important business insights.
Why ETL Process Optimization Matters
Modern businesses depend on timely and accurate information. When data pipelines become slow or unreliable, reporting delays can affect strategic decisions and operational performance.
ETL process optimization helps organizations achieve several important benefits:
- Faster data availability for analytics and reporting
- Improved system performance
- Reduced infrastructure expenses
- Better data quality and consistency
- Enhanced scalability for growing datasets
- Lower risk of processing failures
As data ecosystems become more complex, optimization ensures that ETL workflows remain capable of handling increasing workloads without sacrificing performance.
Identifying Common ETL Performance Challenges
Before improving an ETL workflow, it is important to understand the most common issues that affect performance.
One major challenge is excessive data movement. Extracting large volumes of unnecessary information increases network usage, processing time, and storage requirements. Another common problem is inefficient transformations that consume excessive computing resources.
Data quality issues can also create bottlenecks. Missing values, duplicate records, inconsistent formats, and invalid entries often require additional processing that slows down workflows. Poor indexing, inadequate hardware resources, and outdated ETL tools can further reduce performance.
Recognizing these challenges is the first step toward building a more efficient and reliable data pipeline.
Optimizing Data Extraction
The extraction phase is often the starting point for performance improvements. Extracting only the necessary data significantly reduces processing overhead.
Instead of retrieving entire datasets repeatedly, organizations can implement incremental extraction strategies. Incremental extraction captures only new or modified records since the previous run, reducing both processing time and resource consumption.
Filtering data at the source is another effective technique. Applying conditions during extraction minimizes the volume of unnecessary information entering the pipeline. This approach improves efficiency and reduces downstream workload.
Efficient extraction methods also help reduce network congestion and improve overall pipeline responsiveness.
Improving Transformation Efficiency
Data transformation is frequently the most resource-intensive stage of ETL workflows. Complex calculations, joins, aggregations, and validation rules can significantly impact performance.
One effective strategy is simplifying transformation logic wherever possible. Removing redundant calculations and streamlining workflows can reduce processing times without affecting data quality.
Parallel processing is another powerful optimization technique. By distributing workloads across multiple processors or nodes, organizations can transform larger datasets more quickly.
Many modern ETL platforms also support pushdown optimization, which allows transformations to occur directly within the source or target database. This reduces data movement and leverages the processing capabilities of database engines.
When implemented correctly, these techniques contribute significantly to successful etl process optimization initiatives.
Enhancing Data Loading Performance
The loading phase can become a bottleneck when dealing with large volumes of data. Efficient loading methods help ensure that processed information reaches its destination quickly.
Bulk loading is generally faster than inserting records individually. Many database systems provide specialized bulk load utilities designed to handle large datasets efficiently.
Partitioning data can also improve performance. By dividing large tables into smaller segments, organizations can speed up loading operations and improve query response times.
Another valuable practice is scheduling loads during periods of lower system activity. This minimizes competition for resources and helps maintain consistent performance across the environment.
Leveraging Automation and Orchestration
Automation plays a critical role in modern data management strategies. Automated ETL workflows reduce manual intervention, improve consistency, and decrease the likelihood of human error.
Workflow orchestration tools help manage dependencies, scheduling, monitoring, and recovery processes. These solutions ensure that tasks run in the correct sequence and provide visibility into pipeline performance.
Automated alerts and notifications allow teams to identify and address issues before they impact business operations. By reducing operational overhead, automation contributes directly to more effective etl process optimization efforts.
Monitoring and Performance Tracking
Optimization is not a one-time project. Continuous monitoring is essential for maintaining long-term ETL performance.
Key performance indicators (KPIs) help organizations evaluate pipeline efficiency. Common metrics include:
- Execution time
- Data throughput
- Error rates
- Resource utilization
- Data latency
- System availability
Monitoring tools provide real-time insights into pipeline behavior and help identify emerging bottlenecks. Regular performance reviews allow teams to make proactive improvements and prevent future issues.
Organizations that continuously track performance are better positioned to maintain efficient and reliable data operations.
Improving Data Quality for Better Results
Data quality and performance are closely connected. Poor-quality data often requires additional validation, cleansing, and correction steps that increase processing time.
Implementing strong data governance practices helps maintain consistency across systems. Validation rules should be applied early in the pipeline to identify issues before they propagate through downstream processes.
Deduplication, standardization, and anomaly detection techniques further improve data integrity. High-quality data not only supports accurate analytics but also contributes to smoother ETL execution.
A focus on data quality is a foundational element of successful etl process optimization.
Cloud-Based ETL Optimization Strategies
Cloud technologies have transformed the way organizations manage data pipelines. Cloud platforms offer flexible resources that can scale dynamically based on workload demands.
Auto-scaling capabilities allow organizations to allocate additional computing power during peak processing periods and reduce resources when demand decreases. This improves efficiency while controlling costs.
Cloud-native ETL solutions often include built-in monitoring, automation, and performance optimization features. These capabilities simplify management and help organizations adapt to growing data requirements more effectively.
As businesses increasingly migrate to cloud environments, optimizing cloud-based ETL workflows becomes an important competitive advantage.
Best Practices for Long-Term ETL Success
Maintaining efficient ETL operations requires a combination of technical improvements and operational discipline.
Organizations should regularly review pipeline architecture, update transformation logic, and remove obsolete processes. Documentation should remain current so teams can understand workflow dependencies and troubleshoot issues efficiently.
Performance testing should be conducted periodically to identify bottlenecks before they become significant problems. Capacity planning is equally important for ensuring that infrastructure can support future growth.
Adopting these best practices helps organizations sustain the benefits of etl process optimization over time.
Conclusion
Data has become a critical driver of business success, making efficient ETL workflows more important than ever. Organizations that invest in optimizing extraction, transformation, and loading processes can improve performance, reduce costs, and deliver timely insights to decision-makers.
From incremental extraction and parallel processing to automation, monitoring, and cloud scalability, numerous strategies can enhance ETL efficiency. The key is to view optimization as an ongoing process rather than a one-time initiative.
By implementing proven techniques and continuously monitoring performance, businesses can build resilient data pipelines that support growth, innovation, and informed decision-making for years to come.
FAQs
1. What is ETL process optimization?
ETL process optimization is the practice of improving the performance, efficiency, reliability, and scalability of Extract, Transform, and Load workflows to process data faster and more accurately.
2. Why is ETL optimization important?
It helps reduce processing time, improve data quality, lower infrastructure costs, and ensure that users receive accurate information without delays.
3. What causes slow ETL performance?
Common causes include excessive data extraction, inefficient transformations, poor indexing, inadequate hardware resources, and data quality issues.
4. How does incremental loading improve ETL efficiency?
Incremental loading processes only new or modified records instead of the entire dataset, significantly reducing processing time and resource usage.
5. Can cloud platforms improve ETL performance?
Yes. Cloud platforms provide scalable resources, automated management features, and flexible infrastructure that can improve ETL efficiency and reduce operational complexity.
More Details : Docker Interview Questions: A Complete Guide for Job Seekers